

在当今人工智能和机器学习领域,大规模的计算能力是推动创新和突破的关键。而搭建一个拥有10万个H100 GPU的集群,极具挑战性。
这种规模集群能支持前所未有的模型训练和数据处理任务,对人工智能研究具有重要意义。
然而,搭建这样的集群并非易事,它涉及到电力供应、网络拓扑结构、并行化挑战、可靠性与恢复以及成本优化等。

• 内存:高达80GB的HBM内存,决定了模型可以存储和处理的权重和数据的量。
• 计算能力:提供了高达40 TFLOPS的FP16计算能力,使它成为AI模型的理想选择。
• 功耗:的功率为700W,加上其他功耗,总功耗约为1200W。
• 网络接口:支持NVLink和PCIe,可与GPU及外部存储和网络设备通信。
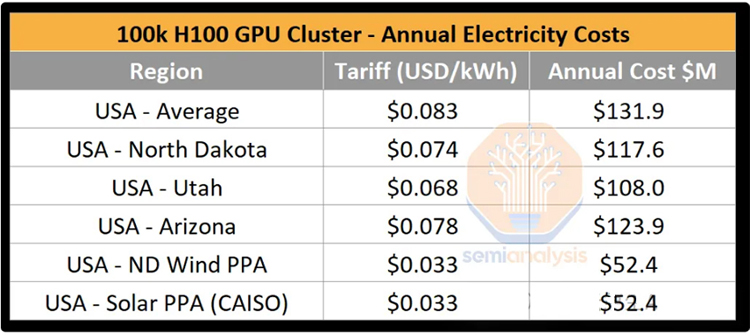
• 年度耗电量:集群的年耗电量约为1.59太瓦时(TWh)
• 电力成本:按照美国电力的标准费率(每千瓦时0.78美元),每年的电力成本约为1.24亿美元。
• 总成本:整个集群的搭建成本大约为40亿美元,这包括了硬件采购、软件许可、数据中心建设、冷却系统、网络设备、运营维护等所有费用。
• H100集群能力:10万卡H100集群的理论峰值性能可达198 FP8或99 FP16 ExaFLOPS,这基于每个GPU的峰值性能和集群的总GPU数量计算得出。
• 训练时间:以OpenAI的GPT-4模型为例,使用FP8精度,10万卡H100集群可以在4天内完成训练,相比使用2万个A100的集群100天的耗时100天的耗时,训练时间大幅缩短,显示了H100集群在处理大规模AI任务时的效率。
• GPT-4算力需求 : OpenAI 为 GPT-4 训练的 BF16 FLOPS 约为 2.15e25 FLOP(2150 万 ExaFLOP)
• 总功率:集群的关键IT部件总功率约为150兆瓦(MW),这相当于一个小型城市的电力需求。
• 设施需求:由于单个数据中心大楼无法承载150兆瓦的负载,集群通常需要分布在多个建筑或整个园区中,这要求有高效的电力分配和冷却系统。
• 光纤收发器成本:随着传输距离的增加,光纤收发器的成本也随之上升,这影响了网络的整体设计和成本效益。
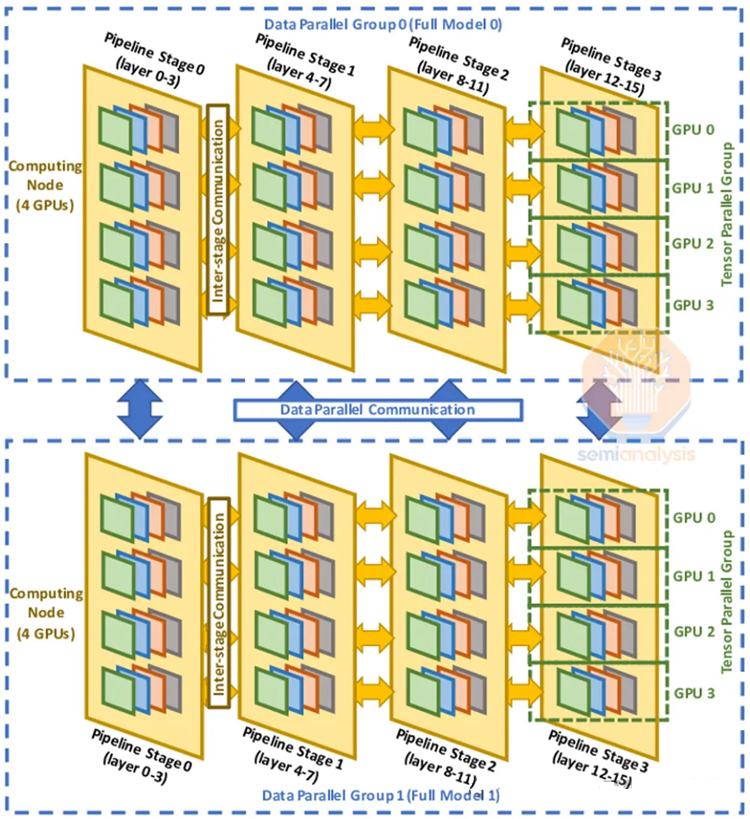
• 数据并行:每个GPU拥有模型权重的完整副本,梯度更新时进行累加。对GPU间通信要求最低,但要求每个GPU有足够的内存。
• 张量并行:神经网络层权重分布在多个GPU上,要求高带宽、低延迟的网络环境,以支持频繁的设备间通信。
• 流水线并行:将前向计算分为多个阶段,每个GPU负责一部分,对跨设备通信的要求较高,且需要精确的同步机制。
• 3D并行:结合数据并行、张量并行和流水线并行,以最大化FLOP利用率,同时解决内存限制和通信瓶颈。
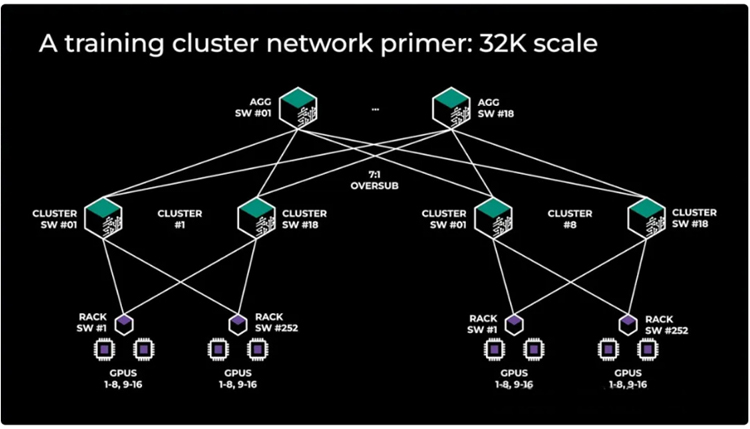
为了降低成本,集群被划分为多个计算岛,每个岛内部带宽高,岛间带宽低,这有助于优化网络架构和减少成本。
网络方案:
• 胖树拓扑:提供高带宽连接,但成本高昂,通常不会用于整个集群,而是用于单个计算岛内部。
• InfiniBand网络:支持SHARP网络内缩减,提高网络带宽,但端口容量较低,适用于需要高带宽的应用。
• Spectrum-X以太网:得到NVIDIA库的一级支持,但需购买特定的收发器,提供了灵活性和可扩展性。
bg left:50% 90%
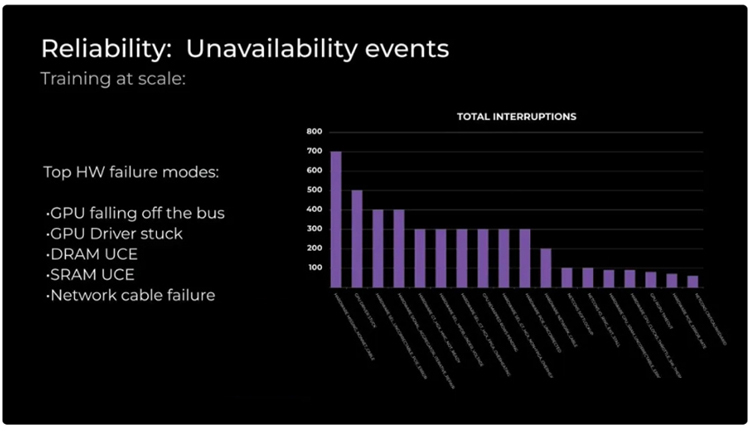
• 故障处理:采用热备用节点和冷备用组件,以减少故障恢复时间,确保集群的高可用性。
• 备份与恢复:定期保存检查点,利用内存重建技术快速恢复故障,减少计算损失,这要求有高效的存储和备份策略。

• 网络模块:使用Cedar Fever-7网络模块代替ConnectX-7,减少收发器数量,降低成本,同时保持网络性能。
• 交换机选择:比较InfiniBand、Spectrum-X和Broadcom Tomahawk 5的成本效益,选择合适的交换机,以平衡性能和成本。
方案1:4层InfiniBand网络,32,768个GPU集群,采用轨道优化设计,7:1收敛比,适用于需要极高带宽的应用。
方案2:3层Spectrum X网络,32,768个GPU集群,轨道优化设计,7:1收敛比,提供了良好的扩展性和成本效益。
方案3:3层InfiniBand网络,24,576个GPU集群,非轨道优化设计,用于前端网络的集群间连接,适合对网络带宽要求不是特别高的应用。
方案4:3层Broadcom Tomahawk 5以太网网络,32,768个GPU集群,轨道优化设计,7:1收敛比,提供了成本效益和灵活性。
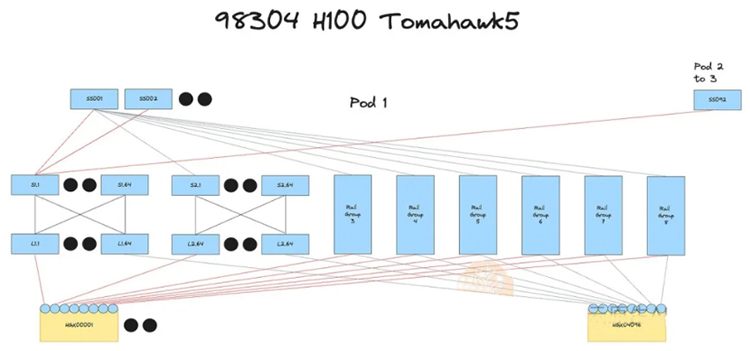
基于博通Broadcom Tomahawk 5的32k集群,搭配7:1的收敛比,被认为是最佳的选择。这种方案在成本、性能和可扩展性之间取得了平衡,是多家公司构建大型GPU集群的首选。
成本与电力估算:
• 年度耗电量约为1.59太瓦时(TWh),年电力成本约为1.24亿美元。
• 总资本支出大约为40亿美元,包括硬件、软件、设施和运营成本。
性能对比:
• 10万卡H100集群的理论峰值性能可达198 FP8或99 FP16 ExaFLOPS。
• 使用FP8精度,4天内可完成GPT-4训练
挑战与解决方案
• 电力挑战:总功率约为150兆瓦,需分布在园区中,并考虑电力供应稳定性和波动。
• 网络拓扑结构:计算岛内部带宽高,岛间带宽低,选择合适的网络方案,如InfiniBand、Spectrum-X和Broadcom Tomahawk 5。
• 可靠性与恢复:采用热备用节点和冷备用组件,以及内存重建技术。
• 成本优化:使用Cedar Fever-7网络模块代替ConnectX-7,以及比较不同交换机的成本效益。
联合工控 版权所有 2002年-2020年 All Rights Reserved 京ICP备13037674号-1
地址(总部):北京市海淀区永丰产业基地丰慧中路新材料创业大厦B座3层
全国统一咨询电话:400-606-9896 (24h)
电话:010-58957780 58957890



