
发展历程:机载显示与国产GPU龙头,从机载市场走向信创市场
景嘉微由国防科技大学团队于 2006 年创立,最早由饶先宏和胡亚华出资设立,同年 曾万辉注资加入公司。公司发展经历了技术积累(2006-2008 年)、业务起步(2008-2010 年)及快速发展(2010 年-今)三个阶段。2007 年公司完成了中航 631 所的项目,开发了 基于 ATI M9(全称 ATI Mobility Radeon 9000)GPU 的图形显控模块,逐渐进入 GPU 研 发领域。公司于 2014 年推出第一代 GPU 产品 JM5400,2018 年第二代核心产品 JM7 系 列面世,2021 年最新的 JM9 系列流片成功,目前公司已成为拥有自主知识产权的国内 GPU 领军企业。公司主要从事高可靠电子产品的研发、生产和销售,产品主要涉及图形显控领域、小 型专用化雷达领域及芯片领域。景嘉微是国内最早系统性研发 GPU 的企业,也是国内唯 一具备完全自主研发独立图形 GPU 能力并产业化的 A 股上市公司。

公司股权结构清晰,实际控制人股权稳定。截至公司 2023 年一季报,公司实际控制 人喻丽丽夫妇共同直接持股 33.38%,同时分别持有景嘉合创 79%、10%的股份,创始团 队及核心技术人员胡亚华、饶先宏分别持股直接 3.43%和 2.13%,同时分别持有景嘉合创 10%、1%的股份,整体股权结构稳定。 国家集成电路产业投资基金为公司第二大股东,持股 8.08%。国家集成电路产业投资 基金最大股东为国家财政部,持股 36.47%。国家集成电路产业基金(简称大基金)的加 入彰显了国家对公司业务发展认可,有助于增强市场信心,但目前已进入回收期,持股比 例比 2021 年的 9.14%有所下降,我们预计未来大基金可能逐步退出主要股东行列。
科技企业对人才的激励十分重要,因此公司推出股权激励计划。2021 年 4 月,公司 通过《关于向激励对象授予股票期权的议案》,向 263 名核心管理及技术骨干授予 749.76 万份股票期权,行权价 68.08 元/股。其中三个行权期行权比例分别为 30%/30%/40%,对 应的行权考核目标分别为净利润增长不低于 2020 年净利润的 30%/50%/100%。2022 年 首个考核目标达成,符合行权条件的 258 名激励对象可申请行权 331.59 万股。

财务情况:营收与归母净利润创新高,芯片成为核心增长点
2022 年公司营收创历史新高,同比增长 5.56%达到 11.54 亿元。2022 年,由于信创 三期验收影响,来自党政信创的订单有所下降,公司利润有所回调,但我们预计随着行业 信创进一步扩展,公司业务有望重回增长轨道。
从具体业务来看,公司自 2016 年上市以来,随着收入规模上升,显控、雷达业务收 入逐渐基本保持平稳增长,但 2022 年增速出现较为明显的上升。2021 年公司图形显控和 雷达领域营业收入同比增长分别为12.35%和8.52%,2022年增速则分别大幅增加到25.01% 和 101.30%。2022 年公司芯片类业务(GPU 业务)实现营收 2.60 亿元,增速有所回调, 主要是受信创进度影响。但公司芯片业务已经具备了一定的实力,JM7 系列 GPU 具备支 撑民用信创市场的性能水平,进而在民用信创市场迅速普及,GPU 业务仍有望成为公司未 来业绩增长的主要驱动力之一。
毛利率方面,近年来公司整体毛利率始终保持在 60%以上,其中图形显控和雷达产品 毛利率可达 70%以上,而 GPU 则处于 50%以下。因此随着 GPU 产品的放量,近年来公 司综合毛利率出现了一定下降,但同时随着研发成本摊薄,GPU 毛利率从 2019 年的 18.57% 上升到2022的47.28%,带动公司整体毛利率再度回升,2022年公司毛利率达到65.01%。
费用率方面,公司销售和管理费用率相对稳定,研发费用率有所提高,2022 年研发 费用率达到 27.07%。近年来公司销售费用率和管理费用率呈现下降趋势,2022 年管理费 用率降至 9.90%,销售费用率降至 4.17%。公司大力投入研发带来技术水平和专利数量的 提升。截至 2022 年底,公司专利申请数达到 238,同比增长 16.10%,其中 193 项为发明 专利,87 项发明专利已授权,且有 119 项软件著作权。
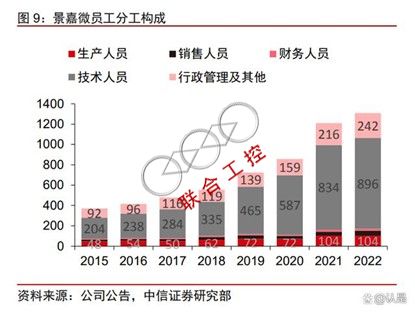
人员方面,公司研发人员占比高,数量稳步提升。公司总人数从 2015 年的 370 人提 高到 2022 的 1308 人。从职能来看,研发人员数从 204 人增加 896 人,规模变为 2015 年的 4 倍以上,研发人员占比从 55.14%提升到 68.50%。从学历来看,硕士及以上学历人 员从 2015 年的 92 人增长到 2022 的 443 人,占比从 24.86%提升到 33.87%。人员规模 与结构的变化有望增强公司研发实力,加快迭代速度。
GPU:并行计算加速硬件,算力与软件支持是关键
GPU的源头:CPU图形算力捉襟见肘,GPU适应图形学并行计算需求
CPU:通用性与效率存在矛盾,为通用性牺牲单一场景性能。 提及 GPU,则自然会关联到 CPU,因为 GPU 可以看作 CPU 的变种。CPU 历史悠久, 核心的 CPU 设计理念,其实早在 1960s 就已经出现了,甚至早于 Intel 和 AMD 两家公司 的诞生,更早于各种图形化操作系统。例如现有 CPU 中必备的流水线、指令动态调度等 核心技术,在 60 年代就已经应用在 IBM 大型机当中。而与之对比,“GPU”这 个名词则是在 1999 年 NVIDIA 发布 GeForce 256 时首次提出的。由此可见,GPU 是 CPU 的后辈,同时 GPU 也是在 CPU 基础上进行针对性改进而生的产品。
因此,要了解 GPU,就有必要对 CPU 进行回顾,从而我们可以了解 GPU 在 CPU 的 基础上进行了哪些改变,以及为什么要进行这些改变。以下是计算机系统的简要框图,其 中 CPU 居于核心地位,CPU 与内存共同构成计算机,CPU 从内存中读数据,进行运算之 后再写回内存,显示在输出设备中。
CPU作为计算机的核心,就要求其必须能够处理人类世界种种纷繁复杂的任务,注 定其将通用性摆在首要位置。那么为了通用性,CPU势必采用最通用的架构设计。这种讲 求通用性的架构设计有何特点?我们不妨从典型的CPU架构中略窥一二。 以下是 Intel 十分经典的 Skylake 桌面处理器单核心架构。从图中左侧我们可以看到, 每个核心可以分成前端(淡黄色底纹部分)、后端(也称执行引擎,淡绿色底纹部分)、缓 存子系统(淡紫色底纹部分)。 前端主要用来进行指令解码、分支预测等,用以应付多种多样、变幻莫测的程序; 缓存用来存储程序所需的指令和数据;后端则是真正将前端处理过后的指令进行执行的部分。
而其实在后端中,真正执行指令的部分占比也不高,因为程序种类繁多,其中的指令 耗费的时间和数据也各不相同,因此后端中相当大一部分芯片面积用于对指令执行顺序进 行动态调度。而真正用于指令执行的,其实只有执行单元(EU,图中深绿色部分)。再进 一步看,EU 部分的 8 个小分组中,有 4 个用于与内存沟通,例如生成内存地址、读写数 据,只有 4 个剩余的 EU 组可以用来真正进行数据计算(图中红色虚线框部分)。而这 4 组 EU 当中,包含 4 个整数加减单元,1 个整数乘法、1 个整数除法、1 个浮点除法单元, 2 个浮点乘加单元,以及 5 个向量运算单元。
可见,如果有大批量的某种单一运算任务(例如数百万次浮点乘除法),那么 CPU 真 正能够利用的计算面积可谓小之又小,效率很低。正如同人体,为了追求通用性,具备各 式各样的结构,但每一种功能都只用到一小部分结构,那么我们在特定任务上的表现往往 不会那么出色,我们对温度的感知能力甚至不如一个简单的体温计。 从 CPU 的架构,我们可以看到,“通用性”和“单一任务效率”始终存在矛盾。CPU 极端倾向通用性,而 GPU 则是牺牲一定程度的通用性来换取单一任务效率提升。
GPU:摩尔定律带来图形化时代,牺牲通用性换取并行计算能力
正如 NPU、DPU 等新类型的处理器,GPU 的诞生也伴随着时代的变迁和现实的需求。 随着摩尔定律持续生效,CPU 能够支撑的运算量越来越大,从而诞生了愈发复杂的程序。 20 世纪 70 年代-90 年代,图形化人机界面(GUI)的操作系统、2D 游戏、3D 游戏先后 出现,对 CPU 的性能提出了越来越高的需求。软件的开发比硬件更为便捷,发展速度超越硬件,导致最先进的 CPU 在应对图形程 序时也会卡顿。因此,开发较 CPU 更高效的硬件势在必行,GPU 应运而生。而其中,最 能够对 CPU 构成挑战的当属 3D 游戏,现代意义上的 GPU/显卡也是在 3D 游戏时代诞生发展的,其典型代表包括 3DFX、NVIDIA、ATI、AMD 等。此外还有 2D 显卡时代的两大 巨头 S3 Graphics、Trident 等公司也在 3D 时代进行尝试,但最终未能取得明显战果。

计算机图形渲染:从三角网格的变形运动到像素填充,存在大量并行性
GPU 为何能够在 3D 时代拯救 CPU 的算力不足?其原因在于计算机图形学算法有其 固定流程和特征,而 GPU 就是针对计算机图形学算法设计而来,从而可以采用与 CPU 不 同的架构,舍弃部分通用性,而增强了并行计算能力。 当代 GPU 的工作主要包括视频编码解码、3D 渲染等工作。其中视频编解码工作往往 可以用专用的电路进行解决,而 3D 渲染相关工作较为复杂。
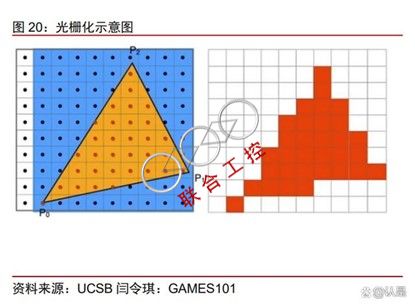
所谓 3D 渲染,也就是将 3D 模型和场景显示到图像上的过程,该流程通常有比较固 定的几个阶段。首先,大多数 3D 模型的轮廓都是由一个个小三角形拼接而成的(3D mesh), 我们首先需要计算出所有小三角形的顶点坐标,才能确定模型的动作姿态。在确定三角形 坐标后,模型表面还没有图案,我们需要进行“贴图”,让模型表面的颜色、纹理、反光 率等情况得到显示。此后为了将图像显示在屏幕上,还需要将模型中各个小三角的位置以 及内部颜色与屏幕上的像素进行一一对应(光栅化)。
具体来说,模型的运动通过诸多小三角形的运动来实现。小三角形通常会有旋转、剪 切、缩放等线性变换,以及平移变换,统称“仿射变换”。这些仿射变换都可以通过矩阵 的方式进行表达,三维空间中的坐标点通过乘以仿射变换矩阵,就完成了变换。由此可见, 模型顶点的变换,其实是通过大量并行进行的乘加运算实现的。而后续的贴图环节,就是将设计好的纹理图“texture”按照对应的坐标关系,一一映 射到“没有皮肤”的模型表面,其本质同样是大量可并行的运算。将模型转化为像素点的 光栅化过程,主要是对像素点对应位置的空间坐标点进行颜色采样,同样是大量的并行运 算。
GPU架构:适应图形需求,一批核心共用控制部分,同时执行同样指令
如前所述,图形渲染需要处理的是大量独立并行的运算任务,GPU 的设计与此相合。 以较为简单的 Fermi 架构为例(该架构于 2010 年推出),可以看到其中计算核心占比 非常高(图中绿色部分)。如果我们进一步拆开来看,打开一个 SM(Stream Multi-processor, 红框中部分),其中包含了 2*16 个计算核心(深绿),16 个读写单元(LD/ST,黄绿),4 个用来计算超越函数的特殊功能单元 SFU(浅绿),数量较多;同时还包含 22 线程束调度 器(Warp Scheduler,橙色),每个线程束调度器可以同时控制 16 个计算核心,让这些核 心同时执行相同的指令。
对比 CPU 架构来看,可以发现 CPU 中 EU 只占很小一部分,而 GPU 中计算核心占 据大多数面积。由于无需考虑指令之间的相互依赖关系,只需对大量数据执行同样的操作, 因此 GPU 无需 CPU 中那么复杂的控制单元(前端以及指令调度部分)。可以说,是图形 应用的特殊性给了 GPU 改进的空间,使其可以舍弃部分通用性设计,专注并行计算效率。
联合工控 版权所有 2002年-2020年 All Rights Reserved 京ICP备13037674号-1
地址(总部):北京市海淀区永丰产业基地丰慧中路新材料创业大厦B座3层
全国统一咨询电话:400-606-9896 (24h)
电话:010-58957780 58957890



